
 Artetsu Saria 2005
Artetsu Saria 2005
Arbaso Elkarteak Eusko Ikaskuntzari 2005eko Artetsu sarietako bat eman dio Euskonewseko Artisautza atalarengatik
 Buber Saria 2003
Buber Saria 2003
On line komunikabide onenari Buber Saria 2003. Euskonews y Media
 Argia Saria 1999
Argia Saria 1999
Astekari elektronikoari Merezimenduzko Saria
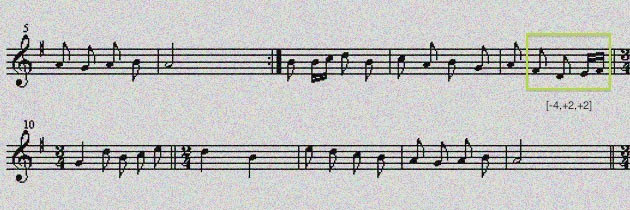
Darrell CONKLIN, Department of Computer Science and Artificial Intelligence University of the Basque Country and Ikerbasque Foundation
In recent years there has been a renewed interest in folk song analysis, due to interest in cultural heritage and by advances in music informatics methods. The ability to analyse music content for different properties of songs such as place name, dance type, tune family, tonality, and social function, is an important part of the management and understanding of large corpora.
This article describes a collaborative project among three entities in the Basque Country: the Euskomedia Foundation, the Eresbil Foundation , and the principal investigator, an Ikerbasque Research Professor in the Department of Computer Science and Artificial Intelligence at the University of the Basque Country.
The objective of the project is the analysis of musical properties of Basque song collections through automated pattern discovery. This project will open new paths in the study and analysis of essential elements of Basque music, helping to understand the study of the evolution and origins of Basque melodies, and will lead to methods for automatic classification of songs.
The interest of the Euskomedia Foundation in the research project arises from their project “Basque Songbook”. The Eresbil Foundation has participated in the process of editing the Cancionero Vasco of P. Donostia (˜1900 songs) and the Cancionero Popular Vasco of R.M. Azkue (˜1200 songs). Eresbil acted as coordinator of the contents of the Basque Songbook project of the Basque Studies Society, a project to host traditional Basque songbooks in a database for search and dissemination.
Songs in the Basque Songbook contain two important types of information: musical data (in MIDI format) that encodes the melody, and metadata that represents global features including the features of place name (of collection of the song) and genre (indicated by musicologists) that are the most important for our study. In the Cancionero Vasco collection a total of 24 distinct genres are referenced, besides place names organized in levels of region, municipality, and town. As indicated below, each place names or genre is linked with a class of an ontology, and we use data mining algorithms to find associations or rules between musical content and the class of songs.
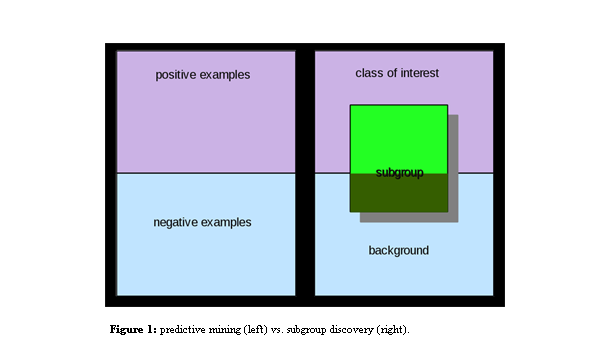
Data mining comprises techniques for the extraction of knowledge in large databases. Today, data mining is used in all fields of study of the natural and social sciences, including in the humanities. Most successes of data mining have used predictive methods, in which the objects (songs, images, etc.) are labeled as positive or negative, and the methods attempt to learn rules automatically to separate these two classes and to predict with accuracy the class of new objects encountered in the future. Figure 1 (left) illustrates a set of objects divided into positive (purple) and negative (blue) examples.
In the Cancionero Vasco there are 341 songs without an indication of genre, and more than 200 without an indication of place name. Predictive data mining methods can be used to predict a possible class for each of these, and also for new songs collected by musicologists in the future.
In recent years a new data mining paradigm has emerged, called subgroup discovery (SD) (Kralj Novak et al. 2009)1, which does not attempt to learn rules describing all positive examples, but only a subset (subgroup) among them. Figure 1 (right) shows in purple a class of interest (which can be any of our place names or genres) and in blue the background (all other classes). In contrast to predictive methods, SD must realize two tasks: identify the interesting subgroups then (in fact, in parallel) describe them with comprehensible patterns. Furthermore, the patterns learned by SD do not apply to any example, rather only to those forming part of the subgroup identified (green regions in Figure 2).
To extend SD towards music, Conklin (2010)2 presented the idea of using sequential patterns to describe subgroups. A sequential pattern in music is a sequence of features of notes, for example, [+2,+1] is a sequence of intervals between notes that has instances (for example) the note sequences [C,D,Ef] or [D,E,F].
To discover patterns in this project we will use the method called MGDP (maximally general distinctive pattern) of Conklin (2010) that discovers associations between patterns and classes. The two important concepts of the methods are distinctiveness and generality. It is important to order the results primarily by measure of statistical association. For example, Figure 2 shows a contingency table for an interval pattern [-4,+2,+2] that describes a subgroup of songs of the genre wedding song. The pattern appears in 5/6=83% (light green region divided by purple region) of wedding songs, but only in 365/1892=19% (dark green region divided by blue region) of songs from other genres. It can be said that this pattern is distinctive of wedding songs, because its relative frequency in that class is much higher than in the background.
Additionally the concept of generality or subsumption is very important to structure the search and presentation space of patterns. We say that a pattern is subsumed by another if all songs that contain the pattern also will contain the other (for example, the pattern [+2] subsumes the pattern [-4,+2,+2]). The MGDP algorithm discovers a set of patterns that are both distinctive and among those the most general (not subsumed by any other distinctive pattern). The algorithm was applied with success to folk music of Crete (Conklin y Anagnostopoulou 2011)3.

Subgroup of wedding song:
http://www.euskomedia.org/cancionero/001941
http://www.euskomedia.org/cancionero/002092
http://www.euskomedia.org/cancionero/001816
http://www.euskomedia.org/cancionero/002410
http://www.euskomedia.org/cancionero/001616
An ontology is a structuring of classes in a hierarchical form. In this project we take advantage of the natural hierarchies of place names (regions, municipalities, and towns) that include songs within classes of different sizes.
Ontologies are important as they provide larger classes for analysis. It has been found that the best predictive methods for folk song classification (Hillewaere et al. 2009)4 have a low accuracy in the Cancionero Vasco, because the collection contains many classes with very few examples (for example, the class of wedding song above has only 5 examples), a difficult scenario for predictive data mining. Also we know that genres are fluid, that is, a song can have more than one function or genre, but the musicologist may have only annotated one. The creation of ontologies with more general classes will permit the discovery of more frequent patterns in our song collections.
All ontologies used in this project will be coded in OWL (Web Ontology Language). OWL is a powerful logic formalism that can represent sequential patterns in addition to the basic classes derived from metadata. There is a large community of OWL users, and also tools for OWL that allow visualization, editing, and automated classification of classes into an existing ontology.
The project “Análisis Computacional de la Música Folclórica Vasca” has received initial funding in the first year from the Diputación Foral de Gipuzkoa. The initial tasks of the project will be the following:
After the initial tasks, we plan to continue with the coding of sequential patterns in OWL, consider new data mining scenarios based on ontologies, and advance predictive data mining methods to classify unlabelled songs. It is hoped that the project will open an important step towards the computational analysis of Basque music.
References:
1 Petra Kralj Novak, Nada Lavrac, Geoffrey I. Webb
Supervised descriptive rule discovery: A unifying survey of contrast set, emerging pattern and subgroup mining.
Journal of Machine Learning Research, 10:377-403, 2009.
2 D. Conklin. Discovery of distinctive patterns in music.
Intelligent Data Analysis, 14(5), 547-554, 2010.
3 D. Conklin and C. Anagnostopoulou.
Comparative pattern analysis of Cretan folk songs.
Journal of New Music Research, 40(2):119-125, 2011.
4 R. Hillewaere, B. Manderick, and D. Conklin.
Global feature versus event models for folk song classification.
ISMIR 2009: 10th International Society for Music Information Retrieval Conference,
Kobe, Japan, 729-733, 2009.
Comments:
comments powered by Disqus
